Automatic Text Recognition (ATR) - Getting Started
This session outlines the entire workflow of humanities research projects utilising ATR to extract full text from scanned images. We provide an overview of each step in the process and introduce subsequent tutorials that delve deeper into these steps. Additionally, a workflow on ‘How to get started with ATR’ road map linked in the conclusion will guide you through important questions and give you basic orientation before starting an ATR project.
This is the English version of this training module. The video is available with English, French and German subtitles.
Si vous souhaitez accéder à la version française du module, rendez-vous ici.
Die deutsche Version der u.s. Lerneinheit ist hier verfügbar
Learning Outcomes
After completing this resource, learners will be able to:
- Identify the components of the ATR workflow relevant to humanities research.
- Understand the basic principles and applications of Automatic Text Recognition.
- Prepare their journey through the ATR pipeline by using our roadmap “How to get started in ATR?”
- Prepare to integrate ATR technology into your research activities effectively.
How to prepare my corpus?
The first step is to get images of the text you want to transcribe.
The second step is to optimise images. To find out more about the required image quality and preparation prior to uploading, please refer to the training module: “Image optimisation“.
Once your images are optimised, you upload them onto a transcription platform. In this training module series, we use the French platform, eScriptorium. However, the process is the same when using other platforms such as Transkribus or OCR-D. Moreover, there is no difference between transcribing images of handwritten manuscripts and printed text.
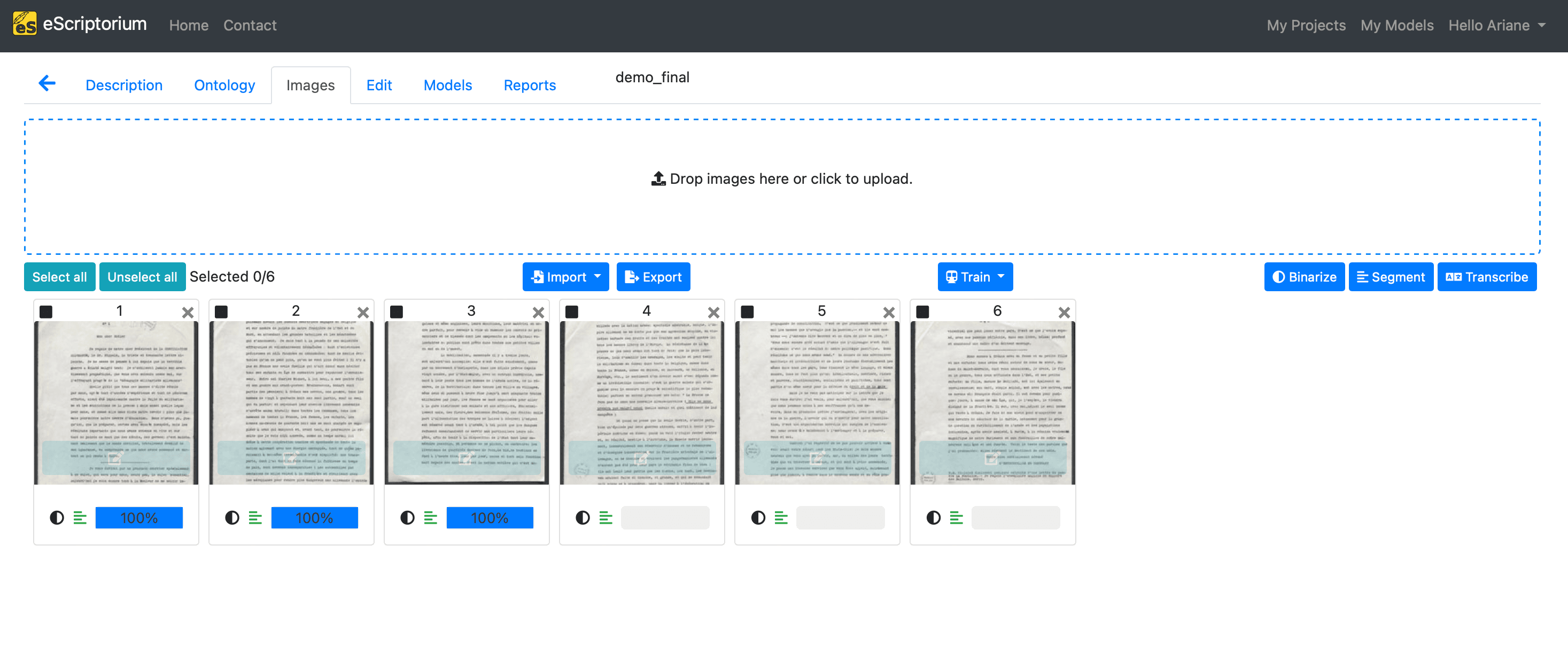
Example of uploading an image to eScriptorium
Layout analysis
The third step is the layout analysis. The software recognises zones of text on a page. In other words, it distinguishes between areas with text and areas with other non-textual content or no content at all. Segmentation is the process by which a digital image is divided into several zones corresponding to the layout of the document. Segmentation itself can be broken down into two different steps: recognition of text zones, and recognition of the lines of text within the zones.
The layout analysis step is essential for defining the layout of the text and locating the titles, subtitles, margins or annotations that accompany the main body of text. To go further refer to the training module: “Layout analysis”.

Segmentation example from the Gallic(orpora) project with three different zones
Text recognition and model training
Once the areas and lines of text have been recognised, the next step is to predict the content of the text. It is important to understand that the machine does not actually read the text like the human eye does. It actually predicts the probability of a combination of letters or a specific word appearing. The time taken by this prediction process depends on several factors, such as the number of images or the performance of your computer.
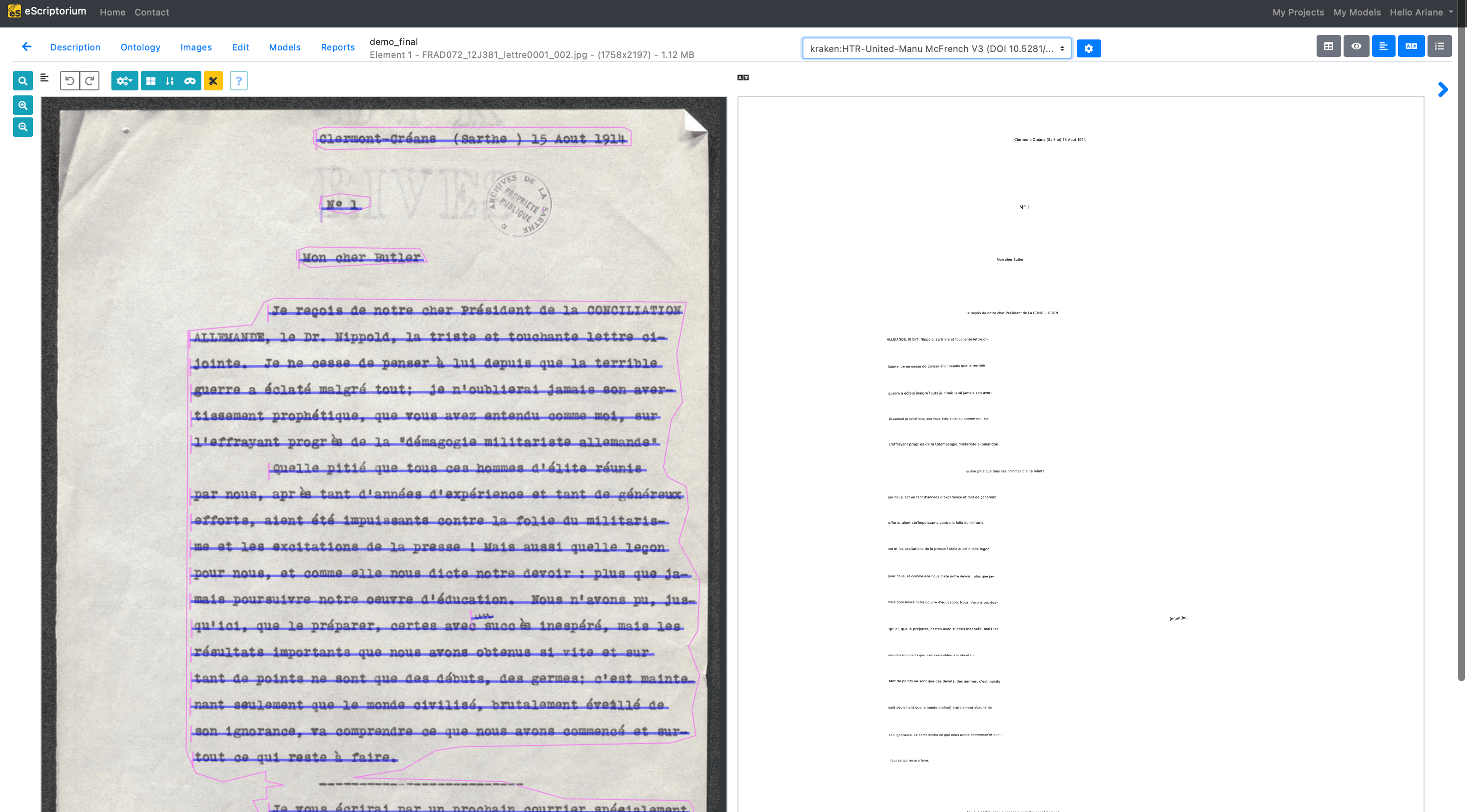
Example of Text Recognition
Model training is at the core of the ATR process. A model is a file that is created, improved and trained based on preexisting training data. This training data is also known as ground truth data. It consists of several pages of transcriptions aligned line by line with the images. These transcriptions are made and checked manually by a person. This correct transcription is considered as “the truth”, and the artificial intelligence uses it to learn to distinguish the correct sign.
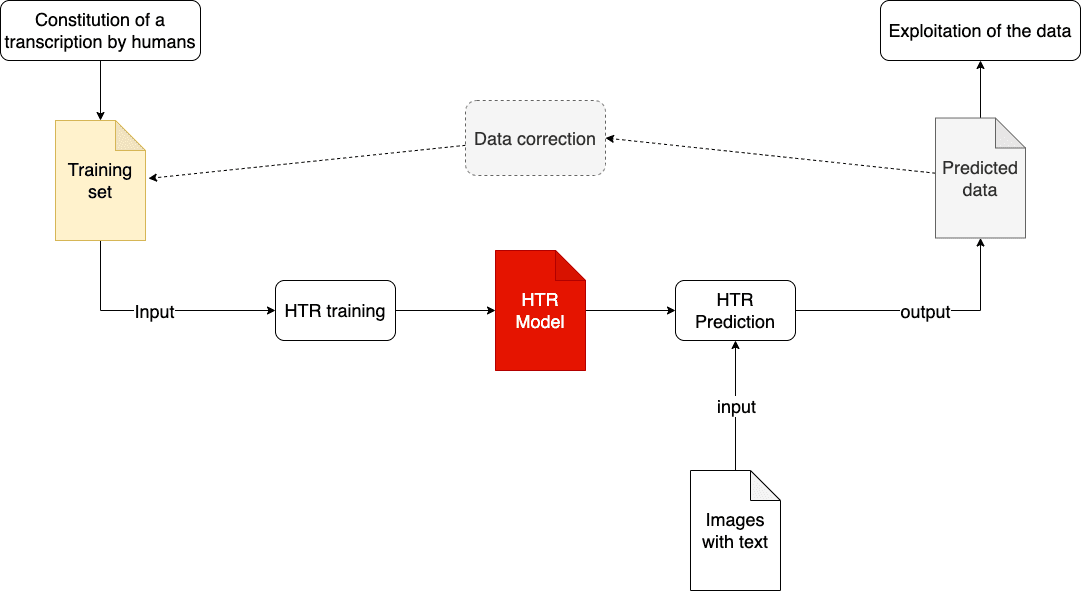
ATR Training Cycle
To train a model, there are two options: either create a new model from scratch or enhance an existing model by fine-tuning it for your own sources, essentially turning it into a fine-tuned model.
- Building a model from scratch demands a substantial volume of training data, which can amount to over a hundred pages of manually- transcribed text– especially when your corpus is very heterogeneous. It involves a significant investment in terms of time, computing resources and technical expertise, as you will be responsible for all aspects of the training.
- Fine-tuning a model involves incorporating your own data into a generic ATR model, customizing this generic model to suit your specific corpus. There are several reliable sites and repositories where you can find pretrained models as HTR-United and Zenodo.
Quality assurance and metrics
Once the model has produced the transcription, you will have to check its performance. This is the fifth step: quality assurance and metrics. In the ATR transcription, several types of errors can occur, such as the addition of a sign that does not exist in the original text, the deletion of a sign, the replacement of one sign by another, etc.

Types of Transcription Errors
The performance of a model in predicting a text is evaluated types of score. The most common are accuracy and character or word error rate. The character error rate (CER) compares the total number of characters of the test set, including spaces, to the addition of the number of insertions, substitutions and deletions of characters that are required to obtain the ground truth result. Each minor transcription error is an error. This means that every missing comma, the identification of a “u” instead of a “v”, an additional space or even an uppercase letter instead of a lowercase letter are included in the CER as errors.
The accuracy rate is a good indicator of the performance of the model used, but the score to be achieved depends on the desired goal.
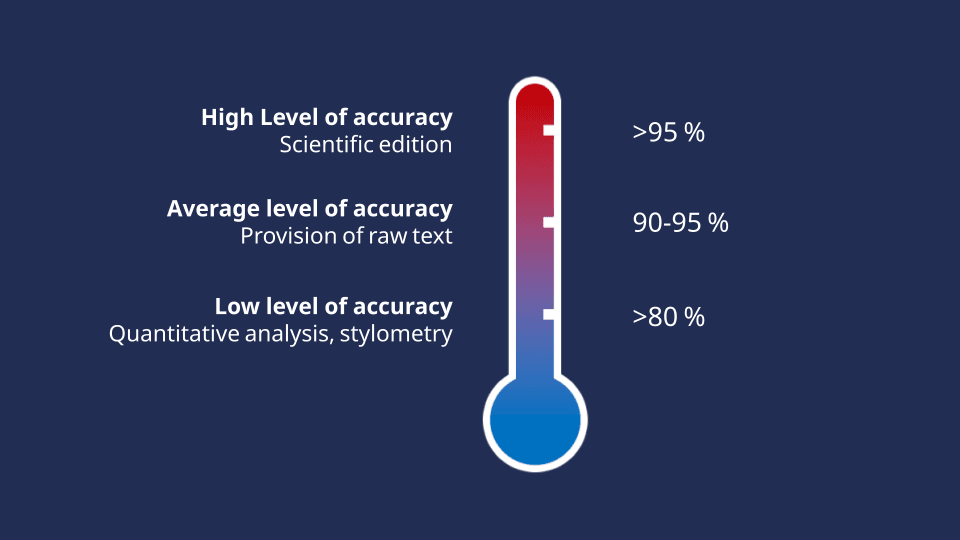
Use according to accuracy rate in per cent
For a scholarly edition, an accuracy rate of over 95% is required. For the provision of raw text, an accuracy rate of over 90% is sufficient, while statistical analyses can be carried out using a model offering 85% accuracy.
It is important to note that these scores do not have the same significance depending on the diversity of the training corpus. The greater the diversity in the model’s training corpus, the more data it requires to achieve higher accuracy. However, with a diverse training corpus, the model is more likely to successfully adapt to an unknown document, even if its accuracy score may be lower than that of a model trained on a single manuscript, for example.
Endformat and reusability
Once the transcription has been predicted by the machine and corrected by a human, the final stage is to export the result from the transcription platform. There are several possible formats for this, such as raw text or XML formats. The choice depends on the goal: what do you need the transcription for? Our video dedicated to these topics and the road map can help you choose the most suitable format.
Conclusion: Start with a strategy… and a road map
Automatic text recognition offers a wide range of possibilities. However, you need to develop a real strategy beforehand to determine whether this technique is suited for your needs. We designed a road map to help you identify and answer key questions about your research design, your available financial and technical means, as well as your infrastructure. It will also guide you in selecting a suitable existing model. This guide will help you adopt good scientific practices in data sharing, in line with the FAIR principles.
Interesting in learning more? Why not continue with the ATR roadmap workflow on the SSH-Open Marketplace?